Stage 3: Complying with VRC-15 (Data Access)
Looking for the latest setup guide?This page is outdated. We’ve released a fully updated guide with everything you need to launch a DataDAO using the latest tools: VRC-20 contracts, contributor UI, PoC, refinement, and more.
👉 Follow the new step-by-step guide
It’s the fastest and most reliable way to get started today.
1. Introduction
Overview of Data Access in Vana
The Vana ecosystem is evolving to support data access, allowing DataDAOs to make their collected data available to application builders in a secure, controlled, and monetizable way. This represents a significant advancement for the ecosystem, opening new revenue streams for DataDAOs while enabling the development of valuable applications.
Benefits for DataDAOs
- New Revenue Streams: Monetize your data by providing secure access to application builders
- Governance Control: Maintain fine-grained control over who accesses your data and at what price
- Data Security: Ensure your contributors' data remains secure with advanced encryption
- Ecosystem Participation: Play a critical role in the Vana data economy
Key Components
The data access architecture consists of several key components:
- Data Refinement: Process that transforms raw data into queryable format
- Data Refiner Registry: Smart contract storing schema information
- Query Engine: Provides secure access to refined data
- Compute Engine: Executes jobs that interact with the Query Engine
- Permission System: Controls access to data at various levels
This guide will walk you through each step of preparing your DLP for data access integration.
2. Data Refinement Process
What is Refinement and Why It's Necessary
Refinement is the process of transforming raw user-contributed data into a structured, queryable format (specifically libSQL, a modern fork of SQLite). This step is essential because:
- It normalizes data into a consistent schema
- It enables SQL-based querying across all data points
- It allows for optional PII (Personally Identifiable Information) removal or masking
- It creates a secure boundary between raw data and query access
Refinement occurs after the proof-of-contribution process and is a required step for making data available through the query engine.
How Refinement Works
Here is an overview of the data refinement process on Vana.
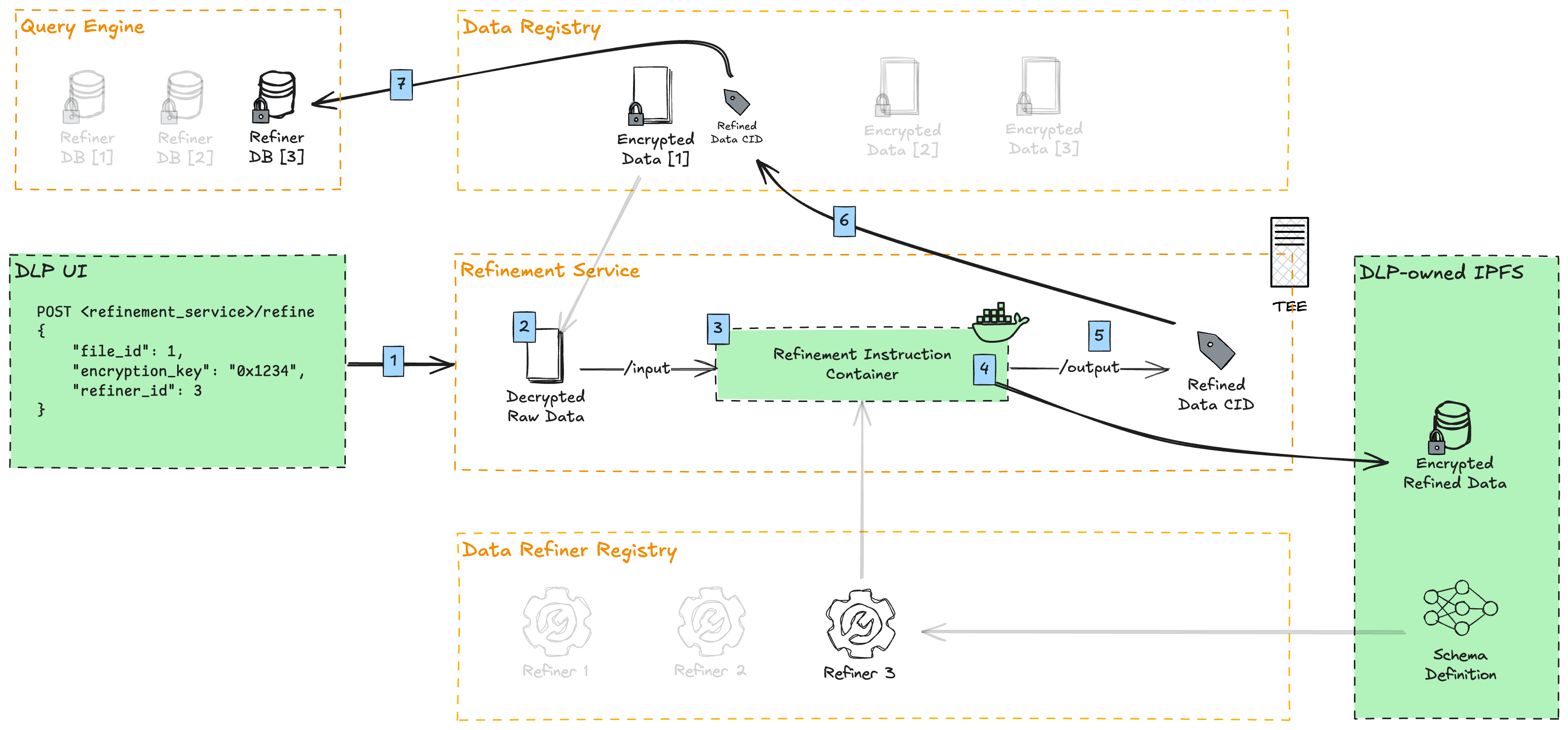
- DLPs upload user-contributed data through their UI, and run proof-of-contribution against it. Afterwards, they call the refinement service to refine this data point.
- The refinement service downloads the file from the Data Registry and decrypts it.
- The refinement container, containing the instructions for data refinement (this repo), is executed
- The decrypted data is mounted to the container's
/inputdirectory - The raw data points are transformed against a normalized SQLite database schema (specifically libSQL, a modern fork of SQLite)
- Optionally, PII (Personally Identifiable Information) is removed or masked
- The refined data is symmetrically encrypted with a derivative of the original file encryption key
- The decrypted data is mounted to the container's
- The encrypted refined data is uploaded and pinned to a DLP-owned IPFS
- The IPFS CID is written to the refinement container's
/outputdirectory - The CID of the file is added as a refinement under the original file in the Data Registry
- Vana's Query Engine indexes that data point, aggregating it with all other data points of a given refiner. This allows SQL queries to run against all data of a particular refiner (schema).
The Refinement Template
Vana provides a template repository that you can fork and customize for your DLP's specific data structure.
Building Your Refinement Docker Image
- Fork the Template: Start by forking the refinement template repository
- Update Models:
- Modify
refiner/models/unrefined.pyto match your raw data structure - Modify
refiner/models/refined.pyto define your target SQLite schema
- Modify
- Customize Transformers:
- Update
refiner/transformer/files to map your raw data to refined models
- Update
- Configure Settings:
- Get your
REFINEMENT_ENCRYPTION_KEYfrom dlpPubKeys - Modify
refiner/config.pywith your schema name, version, and other parameters
- Get your
- Customize entrypoint:
- If needed, modify
refiner/refiner.pywith your file(s) that need to be refined
- If needed, modify
- Build and Test:
- Test locally with sample data
- Build a Docker image
- Publish the Docker image to a publicly accessible location
PII Considerations and Best Practices
While Vana does not strictly enforce PII removal, it's recommended to consider:
- Masking Identifiers: Use techniques like hashing for emails, usernames, etc.
- Data Minimization: Only include fields necessary for the intended use cases
- Aggregation: Consider aggregating data when individual records aren't needed
- Pseudonymization: Replace direct identifiers with pseudonyms
Remember that you can create multiple refinement types from the same data, perhaps one with PII and one without, each with different access controls.
This is also a great place to enrich your dataset, for example, by calling an API and attaching supplementary data to your original data point.
3. Schema Registration
Creating and Uploading Your Schema
Your schema defines the structure of your refined data. It should:
-
Be created as a JSON file following the proper format:
{ "name": "spotify", "version": "0.0.1", "description": "Schema for storing music-related data", "dialect": "sqlite", "schema": "CREATE TABLE IF NOT EXISTS \"albums\"\n(\n [AlbumId] INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,\n [Title] NVARCHAR(160) NOT NULL,\n [ArtistId] INTEGER NOT NULL,\n FOREIGN KEY ([ArtistId]) REFERENCES \"artists\" ([ArtistId]) \n\t\tON DELETE NO ACTION ON UPDATE NO ACTION\n);\n..." } -
Include all necessary tables, columns, constraints, and relationships
-
Be uploaded to IPFS to obtain a permanently accessible URL
The refinement template includes utilities to help generate this schema from your SQLAlchemy models and upload it to IPFS.
Registering with the DataRefinerRegistry Contract
Once your schema is uploaded to IPFS, you need to register it with the DataRefinerRegistry contract:
- Call the
addRefinerfunction with:dlpId: Your DLP's IDname: A name for your schema/refinerschemaDefinitionUrl: IPFS URL where your schema is storedrefinementInstructionUrl: URL to your Docker imagepublicKey: The public key provided to you by Vana for encrypting refinements
Example:
// This transaction must be sent from your DLP's owner wallet
dataRefinerRegistry.addRefiner(
myDlpId,
"Spotify User Data",
"https://ipfs.vana.org/ipfs/Qma3dWDFZCQnWFTv1owAXyJjtpxjENGvKizPhFT4fsX8do",
"https://github.com/vana-com/vana-data-refinement-template/releases/download/v4/refiner-4.tar.gz",
"0x04bfcab8282071e4c17b3ae235928ec9dd9fb8e2b2f981c56c4a5215c9e7a1fcf1a84924476b8b56f17f719d3d3b729688bb7c39a60b00414d53ae8491df5791fa"
)The contract will assign a unique refiner ID to your schema, which will be used to reference your schema in queries.
You can register multiple refiners for different types of data or different views of the same data, eg:
- Separate refiners for different data sources or types
- One refiner with PII and another without
- New refiners for major schema changes
Each refiner gets its own ID and permissions, allowing you to control access granularly.
4. Refinement Service Integration
Using the Refinement Service API
Vana provides a refinement service that runs your Docker image to process data:
- You can use Vana's hosted service or self-host (recommended)
- The service is hosted in a TEE (Trusted Execution Environment) for security
- The code is available at:
<Anchor label="https://github.com/vana-com/vana-refinement-service" target="_blank" href="https://github.com/vana-com/vana-refinement-service">https://github.com/vana-com/vana-refinement-service</Anchor>
Invoking Refinements for New Data
After proof-of-contribution is run for a new data point, call the refinement service:
POST <refinement-service-url>/refine
{
"file_id": 1234, // File ID in the Data Registry
"encryption_key": "0xabcd1234...", // User's original file encryption key
"refiner_id": 12, // Your refiner ID from the Data Refiner Registry
"env_vars": {
PINATA_API_KEY: "xxx",
PINATA_API_SECRET: "yyy"
}
}The service will:
- Download and decrypt the original file
- Create a refinement encryption key (REK), derived from the original file encryption key, and inject it into your refinement container so your refinement can be encrypted
- Run your refinement Docker container
- Add the refined data to the Data Registry via
addRefinementWithPermission - Grant permission to the query engine to access the refinement, by encrypting REK with the public key from your refiner
Batch Refinement for Existing Data
For refining data collected before implementing VRC-15:
- DLPs can collect a list of file IDs and corresponding encryption keys
- For each file, call the refinement API
This enables you to make your existing data queryable
5. Permission Management
Understanding the Permission Model
The Query Engine contract manages permissions for data access at three levels of granularity:
- Schema Level: Grant access to an entire schema
- Table Level: Grant access to specific tables within that schema
- Column Level: Grant access to specific columns in specific tables within that schema
Permissions are managed by DLP owners and stored on-chain for transparency and security.
Granting Permissions to Application Builders
After negotiating with application builders off-chain:
-
Call the
addPermissionfunction on the Query Engine contract:queryEngine.addPermission( "0x123...", // Grantee: Address of the application builder 12, // Refiner ID: Your schema ID "users", // Table Name: Optional, for table-level permission "email", // Column Name: Optional, for column-level permission "5000000000000000000" // Price: 5 VANA tokens per query ) -
The application builder will then be able to query your data by paying the specified price
-
Revenue is distributed with 80% going to your DLP and 20% to Vana
Managing Generic Permissions
You can also grant permissions to anyone (not just specific addresses):
queryEngine.addGenericPermission(
12, // Refiner ID: Your schema ID
"users", // Table Name: Optional, for table-level permission
"name", // Column Name: Optional, for column-level permission
"1000000000000000000" // Price: 1 VANA token per query
)
This allows any user to access the specified data by paying the set price.
Revoking and Updating Permissions
You can manage existing permissions with:
-
Update Approval: Revoke or reapprove permissions
queryEngine.updatePermissionApproval( permissionId, // The ID of the permission false // Set to false to revoke, true to approve )
6. Pricing and Revenue
Setting Prices for Data Access
When setting prices for your data, consider:
- What unique value does your data provide?
- Higher quality data can command higher prices
- Different tables or columns may have different values
- What are comparable DLPs charging?
- Are you targeting high volume or high value?
Prices are set in $VANA tokens and are charged per query. For v0, pricing is deterministic. If a user is granted permissions to run a query on a schema for a fixed price, if the same query returns 100k records, or 0 records, the user is charged the same amount.
Revenue Distribution
In the current implementation (v0):
- 80% of query fees are reserved for DLPs to manually collect
- 20% go to the Vana data access treasury
Future Pricing Models
In future versions:
- DLPs may be able to charge in their own $DLPT tokens
- More complex pricing models may be supported
- Payment for compute resources may be introduced
7. Security Considerations
Encryption Model and Key Management
The data access system uses the following encryption model:
- Original Data Encryption:
- Raw files are encrypted with the user's wallet signature (EK)
- For others to access, EK is wrapped with receiver's public key and stored in the Data Registry permissions
- Refinement Encryption:
-
A secondary key (REK) is derived from EK using HKDF:
const refinedEncryptionKey = HKDF( hash = 'SHA-256', masterKey = '0xabcd1234...', salt = null, info = `query-engine`, length = 64 ); -
REK is used to encrypt the refined file
-
REK is encrypted with a DLP-specific public key and stored in the Data Registry permissions to grant the Query Engine access to the refinement
-
This prevents the Query Engine from accessing the original data
-
- Key Management:
- Public keys for the Query Engine are generated and provided by Vana
- Each DLP has a specific keypair for their refinements
GDPR Compliance and Takedown Procedures
As a DLP owner, you are considered a GDPR Data Controller, which means:
- You are responsible for user consent and data handling
- You must handle takedown requests if users exercise their right to be forgotten
- When a takedown request is received:
- Stop pinning the relevant files on IPFS
- Work with Vana to ensure any cached data is removed from the Query Engine
Best Practices for Data Security
- Only refine the fields absolutely necessary for your use cases
- Consider masking or removing PII when possible
- Periodically review your permissions and access patterns
- Maintain documentation of your data handling practices
- Be transparent with your users about how their data is used
8. End-to-End Workflow
Step-by-Step Guide
- Preparation:
- Fork the refinement template
- Customize for your data structure
- Build and publish your Docker image
- Create and upload your schema to IPFS
- Registration:
- Register your refiner with the DataRefinerRegistry contract
- Receive your unique refiner ID
- Integration:
- Update your proof-of-contribution workflow to include refinement
- For each new data point:
- Run proof-of-contribution
- Call the refinement service API
- Refinement is added to Data Registry
- Permissions:
- Set up desired permissions in the Query Engine contract
- Negotiate with application builders
- Grant specific or generic permissions
- Monitoring:
- Track queries and revenue
- Respond to new permission requests
- Handle any takedown requests
9. Contract Addresses and API Endpoints
Moksha Testnet & Mainnet:
- DataRefinerRegistry:
0x93c3EF89369fDcf08Be159D9DeF0F18AB6Be008c - QueryEngine:
0xd25Eb66EA2452cf3238A2eC6C1FD1B7F5B320490 - ComputeInstructionRegistry:
0x5786B12b4c6Ba2bFAF0e77Ed30Bf6d32805563A5 - ComputeEngine:
0xb2BFe33FA420c45F1Cf1287542ad81ae935447bd
Service APIs:
- Refinement service:
- Mainnet: mainnet-refiner-1
- Moksha: moksha-refiner-1
- Compute Engine:
- Mainnet: vana-compute-engine-mainnet
- Moksha: moksha-compute-1
Testing and Verification
Before going to production:
- Test your refinement process with sample data
- Verify the schema and refinement output
- Test permission granting and querying
- Validate the encryption and security measures
- Ensure proper error handling and monitoring
By working closely with the Vana team during initial setup, you can ensure a smooth integration with the data access system. Once you’ve confirmed data is refined, encrypted, and queryable in a TEE, you’re set for VRC-15.
Updated 4 months ago