Data Access in Detail
What Is the Vana Data Access Layer?
The Vana Data Access Layer is a core piece of Vana that allows DataDAOs to refine, store, and manage datasets, while enabling developers and data consumers to query and compute on strictly permissioned, structured datasets.
Instead of raw data being openly shared, DataDAOs have direct control over who can query datasets, how computations run, and how data is monetized. This allows data to be used effectively, while still ensuring strict privacy and security policy enforcement.
NoteThe Vana Data Access Layer is currently in closed alpha. Some components may evolve. Contact the team on Discord for early access.
Core Concepts
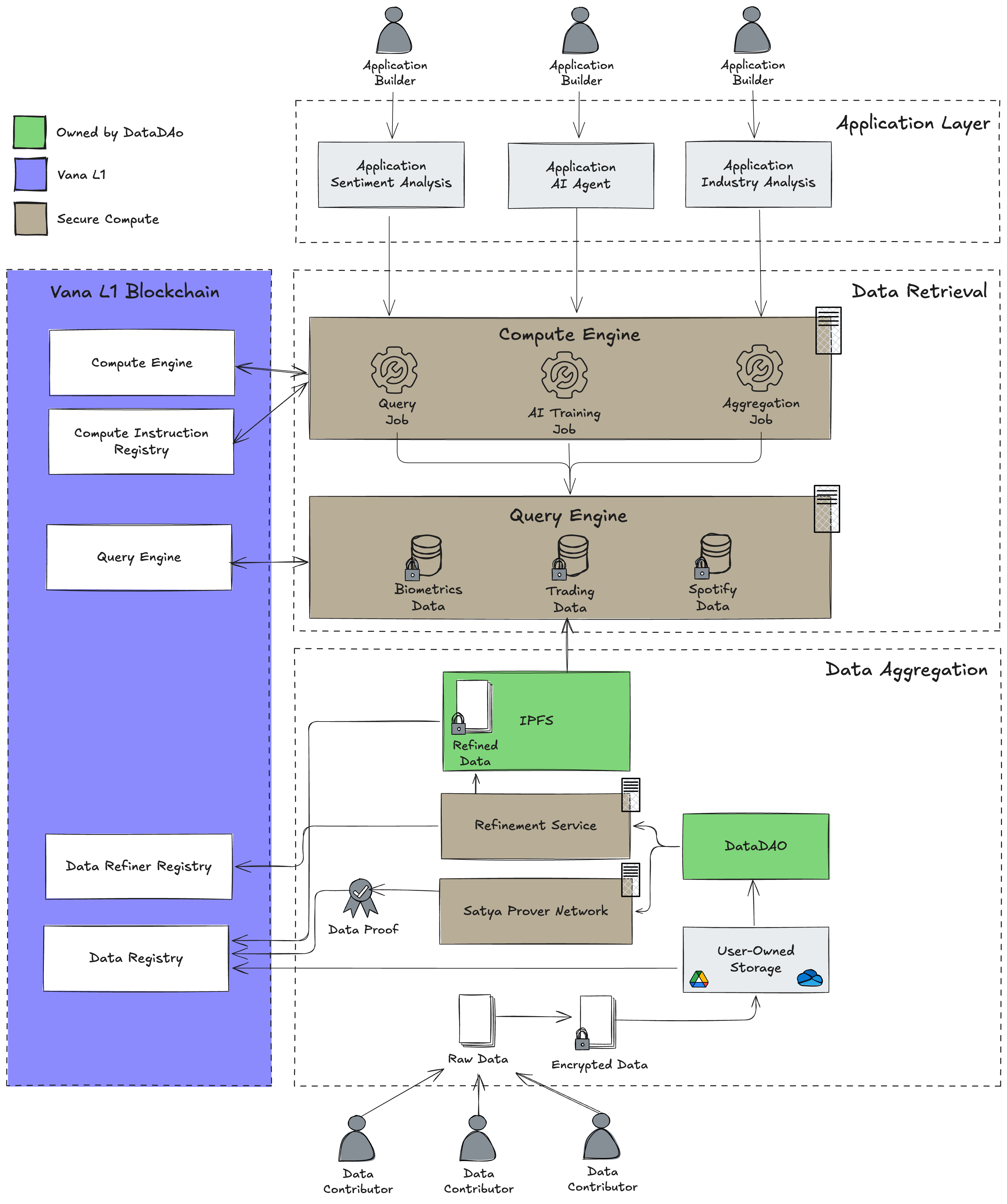
Data Access Layer Overview
Data Refinement
Data refinement is the process of safely transforming raw input data into encrypted, normalized, and queryable datasets.
This is accomplished through publicly documented "data refiners" defined by DataDAOs and DLP owners in their refiner step run through the Satya Prover network.
Query Engine
The Query Engine is responsible for enforcing data access policies, indexing individual data points into efficient aggregate refined datasets, and servicing paid queries against these datasets.
Compute Engine
The Compute Engine manages reusable, composable compute jobs that can query safely against the Query Engine for permissioned users without exposing sensitive information.
Compute jobs can encompass anything from simple query result transformations to AI/ML model training, and they produce downloadable end result artifacts for application builders without providing complete data access. This allows developers and AI researchers to train AI models on data that never leaves the secure environment.
How It Works
Data Providers (DataDAOs) Prepare Datasets
- A DataDAO collects raw data from users or integrated sources.
- The data is "refined" (encrypted, structured, and normalized) within a DataDAO's refiner step and indexed into aggregate, queryable datasets by the new Query Engine component.
- The normalized data structure schema and refinement instructions are created off-chain and documented onchain through the Data Refiner Registry contract.
- The DataDAO sets access policies & data query pricing via its governance in the Query Engine contract.
Data Consumers Request Access
- A developer or researcher discovers available datasets through the onchain Data Refiner Registry contract.
- They request access to specific refined datasets, tables, or columns off-chain directly with the DataDAO.
- The DataDAO submits & approves the request onchain in accordance with their governance rules for a fixed data access price.
- Once permissions are approved, the user pre-pays for query access using $VANA.
Querying & Secure Computation
- The user may register a new compute job template or use an existing one from the Job Registry contract. Jobs can be used to query and transform data, train AI models, or support other use cases.
- They then submit a corresponding compute job to the Compute Engine - to query & transform the data, to train an AI model, etc.
- The Compute Engine job submits a query request to the Query Engine. Queries run on encrypted datasets — no raw data is exposed.
- The user can filter, aggregate, and analyze accessible data determined by DataDAO-defined permissions safely from within the compute job.
- The artifacts produced by the compute engine are provided to the application builder for use in their applications.
Payments & Revenue Distribution
- Query execution costs are determined by individual onchain permission requests on the dataset, table, or column level depending on the value of the target data.
- Once permissions have been granted, any queries can be run with the approved permissions at the determined price, regardless of the amount of data processed.
- DataDAO owners can pre-approve global permissions with fixed prices for their DLP data.
- Payments are made in $VANA, with a 20% commission going back to the Vana network. The remaining 80% is sent directly to the DataDAO in v0. In v1, this portion is used to purchase and burn the DataDAO token.
- Payments flow automatically to DataDAOs and infrastructure providers through the Job Registry smart contract.
- In the future, market- and usage-driven pricing models allow dataset owners to dynamically adjust pricing based on demand.
Why Use the Vana Data Access Layer?
✅ Decentralized Access Control → DataDAOs define permissions — no centralized intermediaries.
✅ Privacy-Preserving Queries → Consumers can extract insights without accessing raw data.
✅ Cross-DAO Querying → Developers can access structured datasets across multiple DataDAOs.
✅ Transparent & Monetized → Payments flow directly to dataset owners based on usage.
✅ Built for Scale → Supports complex queries, high-volume data processing, and ML workloads.
Who Is It For?
- DataDAOs & Data Providers → Structure, govern, and monetize datasets.
- Developers & Data Consumers → Query decentralized data with full transparency.
- AI & Analytics Teams → Run computations on encrypted datasets without exposing sensitive information.
Current Status
The Vana Data Access Layer is currently in private alpha, with select DataDAOs testing its features. While this document presents the target state of the system, some components may evolve. Expect updates as development progresses.
Want to integrate with the Vana Data Access Layer?Contact the team for early access in Builders Discord and explore how to build on top of it.
Updated 4 months ago