Data Retrieval
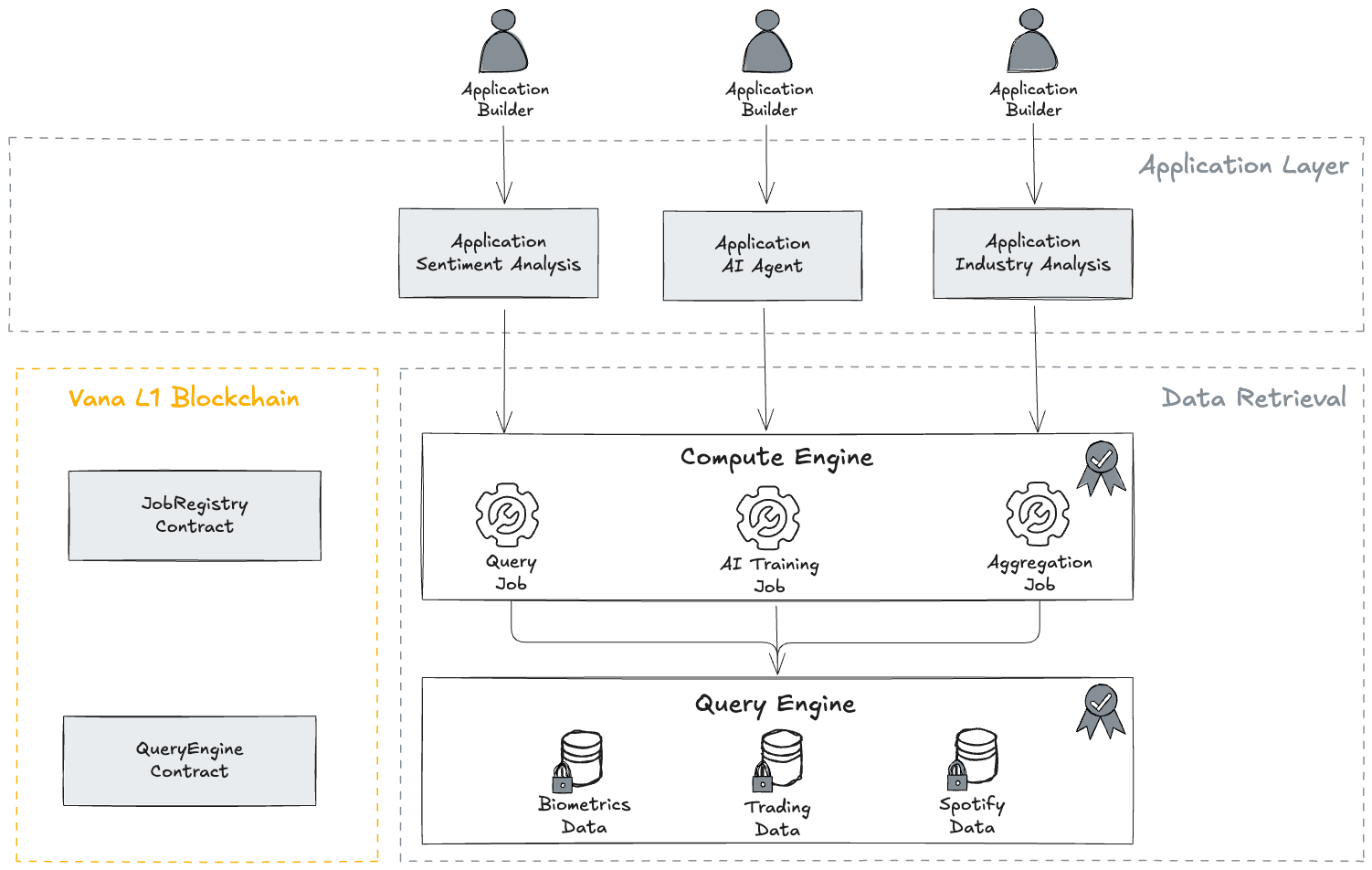
Data retrieval describes the process of consuming ingested, refined data from the perspective of application builders in the Vana Data Access Layer.
Application Query Resolution

Application Query Resolution
The Query Engine services permissioned queries through the Compute Engine against structured DataDAO-managed datasets, while maintaining strict security and compliance controls. It ensures that only verified requestors with explicit DataDAO approval can query refined data.
Query Execution Process
- DataDAOs submit and approve granular permission requests after off-chain negotiations on behalf of requestors for specific schemas, tables, or columns based on their governance policies.
- Approved requestors register a
query-transformCompute Engine job through the Job Registry contract. - Requestors submit the registered job with the returned job ID to the Compute Engine with a query scoped to their authorized data subset.
- Once payment is processed, the Query Engine executes the request and returns time-limited query results through a webhook or parks them for manual retrieval.
Security & Data Protection
To prevent unauthorized access and mitigate data risks, the Query Engine operates under the following constraints:
- Query Engine access is restricted to the Compute Engine to further insulate sensitive data from malicious actors. Data consumers access their query results through the corresponding Compute Engine jobs, not through the Query Engine API directly.
- Successfully queried results expire after a set duration to ensure freshness, comply with intended use mandates (e.g., by GDPR), and mitigate data persistence risks.
Core Capabilities
Query resolution in the data access layer is designed to:
- Enable cross-schema data aggregation by supporting multi-DataDAO queries.
- Enforce zero-trust security by applying encrypted computation and strict permissioned access.
- Optimize query payment and execution leveraging indexed storage and parallelized processing.
- Deliver low-latency insights with fast query execution while ensuring full privacy and security compliance.
Compute Engine
The Compute Engine enables efficient, safe operations on encrypted data as the gateway to the Query Engine. This is achieved by running pre-determined, containerized jobs in a secure execution environment.
Compute Engine jobs are designed to be reusable, composable units for running custom logic safely on sensitive data that builders can hook into. Each job produces one or more artifacts that are available for a set amount of time before they expire.
This enables:
- Custom, query-level data transformations, allowing for flexible usage and customizations.
- AI/ML model training on encrypted datasets without exposing sensitive data.
- Federated data analysis, allowing users to process information across multiple DataDAOs securely.
Permissions & Access Control

Data Access Permissioning Mechanism
Application builders negotiate data access pricing and permissions off-chain directly with DataDAOs based on their individual needs. DataDAOs then register and approve these permissions onchain through the Query Engine contract, opening up data access at the documented price to other potential third-parties.
When DataDAO access & security policies change, permissions can be retroactively revoked to interrupt data access for application builders and safeguard sensitive information. DataDAOs are also provided with a mechanism to compliantly handle individual user takedown requests.
In short, Vana’s onchain permissioning system ensures that data access remains secure, flexible, and transparent by providing:
- Granular control at the dataset, table, and column levels.
- Dynamic permissions, where access can be revoked or updated based on evolving DataDAO policies.
- Multi-party governance, allowing DataDAOs and stakeholders to collaboratively manage permissions.
- Payment-gated access, where users pay $VANA (or future dataDAO tokens) to access specific datasets.
- Deterministic pricing negotiated at the time that permissions are granted.
Pricing & Cost Model
Deterministic pricing and query costs are established when permission requests are submitted to the Query Engine smart contract. Rather than being based on individual queries, pricing is determined by the referenced data - such as schemas, tables, and columns.
DataDAOs also have the option of pre-configuring global permissions with fixed pricing. By submitting and approving these permission themselves through the Query Engine contract, they can set predefined, generic pricing constraints that automatically apply to all users.
When a requestor submits a compute job, its pricing is determined by the most recent permissions they have been granted by the relevant DataDAO(s) that support the query. Before execution, the requestor must prepay the compute engine for future queries through the Compute Engine contract. When queries have successfully completed, payment is automatically deducted and transferred to the Compute Engine for any data access costs or compensation.
In the future, DataDAOs may introduce marketplace-driven pricing, where demand and scarcity dictate costs dynamically.
Updated 5 months ago